
This is the first in a three part series of articles that describes how to create a high availability cluster on Linux.
Below we focus on the basic concepts, discuss configuration prerequisites, and create a basic design.
Actual configuration will take place in the second article in this series. We will conclude in the third article with a presentation of test cases and options for optimization.
Exactly what is a cluster and why do we need them?
In broad terms clustering which is the formation a cluster refers to having two or more computers also known as nodes synchronize timing, processes, and data when working together to complete a task. Clusters can be created at the hardware and software levels. In addition clusters may be formed at any level of the datacenter stack from physical components (controller cards whether storage or network), hypervisors, Operating Systems, and lastly at the userspace level in either the middleware such as the web server or database or in the end user application.
There are three basic motivators for creating a cluster. High performance Computing (HPC), network traffic Load Balancing, and service resilience in the form of High Availability (HA).
HPC or Grid Computing is when a task is broken down into subcomponents and execution of each component is distributed across the nodes in the cluster to improve the speed of computation. The outputs from each node are finally reconstitued to produce the final result.
Load Balancing occurs when production traffic is distributed between nodes in the cluster to reduce the load on any single system. Various algorithms determine the method by which the distribution occurs such as round-robin or least connections etc. Balancing can be done to improve performance and or provide resiliency at the network level. Network load balancing is similar to bonding or teaming at the host level with the exception being that in a cluster case it happens across physical nodes.
High Availability or Failover clustering is done to improve the fault tolerance characteristics of a particular service. In this case services are built up from resource groups that are managed between the nodes. In the event of a fault on any node running a service the affected node is taken out of the cluster that is it is fenced and the service relocated to another healthy node. Common resources found in HA clusters are shared storage devices and virtual IP addresses. Also there will be a fence device with optional heuristics that is used to trigger the reboot or IO restriction for faulted nodes.
Red Hat Cluster Suite (RCS)
RCS is Red Hat's software for creating a HA cluster at the operating system level using Red Hat Enterpise Linux (RHEL).
Package Installation
The following packages will need to be installed on each RHEL node that will join the cluster. rgmanager, lvm2-cluster, and gfs2-utils.
Note that rgmanager is mandatory while the need for the other two packages will depend on whether clvmd or gfs services will be utilized. Optional packages include ricci and luci. These provide a remote API and management web console respectively.
yum install rgmanager lvm2-cluster gfs2-utils;
Cluster Configuration
While RCS supports clusters of up to 16 nodes we will create only a simple two node cluster for this example. Our cluster will manage the failover of a web server (Apache httpd) and database (postgresql).
Prerequisites
- Shared Storage The postgresql data directory and httpd document root will be shared between the nodes in our design. Therefore, that means we will need to use a filesystem that can handle concurrent read and write IOPs and perform locking to maintain consistency. Ideally suited for this task is the GFS2 file system that which we have chosen to utilize for this example.
-
Note: It is possible to create a share nothing cluster in which case data synchronization will have to be performed at the application level. For example, you could use replication at the database level and if the web is stateless or stores all state info in the database then the document root would not need to be shared.
One important requirement when using shared storage in RCS is that the volumes be accessible to all nodes in the cluster at all times. While the file system itself does not need to be mounted at each node it must be accessible. This is because GFS in cluster will reside on LVM volumes managed by clvmd and the meta data must be consistent across cluster members.
Therefore, if you use CIFS or NFS that the filesystem has to be presented to each node or if the storage is provided by a SAN then the LUNs should be zoned to each node and concurrent writes enabled.
-
Seperate Private and Public IP Network subnets will be utilized. The private subnet can use one of the private IP ranges 192.168.*.*, 10.0.*.*, or 172.*.*.*.
The private network needs to support multicast messages and will be used exclusively for the broadcast of the heartbeat messages. Latency on this network needs to be kept at a minimum. Clients and actual services will run on the public network which can be any routable network address.
-
Service breakdown into a list of the basic resources and their dependencies, that is IP addresses, storage, application and or custom scripts that are needed to deliver the service. Each resource will be defined in the cluster configuration file. Finally the resources are bundled into service groups which define the start order and dependencies. The cluster manages service groups not resources.
-
Fence Device. This is a power switch trigger device that the cluster manager will use to issue a reboot when a node is determined to be faulty if using Power Fencing. Ideally this should be an IP based network power switch for example the vCenter server in VMware environments that can used to hard reset a guest virtual machine that acts as a node in the cluster. There are many types including IO Fencing but the exact one chosen will depend on the environment.
-
Cluster Name. Names will be needed for the cluster as well as each member. Use DNS or update the host files on each node to resolve the members by name. All members on every hosts need to be routable by name. Also note that the cluster name is used when generating the locking table by the Dynamic Lock Manager (DLM) so chose the name carefully as while it can changed it requires a little effort if changed later.
-
The following IP ports will need to be allowed on the firewall between the nodes.
| IP Port | Protocol | Cluster Component |
| 8084 | TCP | luci (Conga Web Service) |
| 5404,5405 | UDP | cman (Cluster Manager) |
| 11111 | TCP | ricci (Configuration API) |
| 21064 | TCP | dlm (Distributed Lock Manager) |
| 16851 | TCP | modclusterd |
Example Cluster HLDD
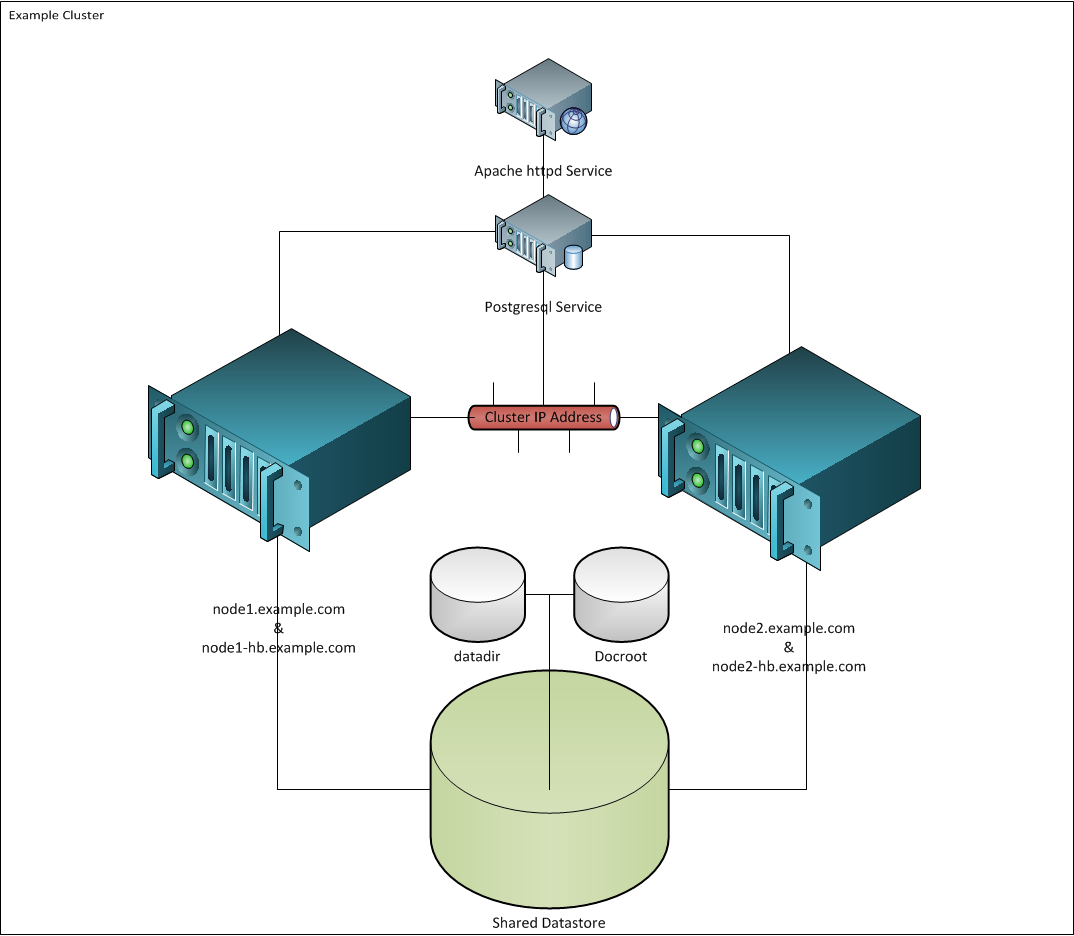
Continue with our guide for Red Hat 7 or go to Part 2 for RHEL 6 and below.
Further Reading
Red Hat Cluster Administration Guide
Enhancing Cluster Quorum with Qdisk
Written by Nneko Branche.
Nneko Branche.